Polyglot Data Management: State of the Art & Open Challenges
(VLDB 2022 Tutorial)
Videos (Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 7, Part 8, Part 9)
Felix Kiehn† (felix.kiehn@uni-hamburg.de), Mareike Schmidt† (mareike.schmidt-3@uni-hamburg.de), Daniel Glake†‡ (daniel.glake@uni-hamburg.de), Fabian Panse† (fabian.panse@uni-hamburg.de), Wolfram Wingerath§ (wolle@uni-oldenburg.de), Benjamin Wollmer†¶ (benjamin.wollmer@uni-hamburg.de), Martin Poppinga† (martin.poppinga@uni-hamburg.de), Norbert Ritter† (norbert.ritter@uni-hamburg.de),
† University of Hamburg (Databases and Information Systems, DBIS), Hamburg, Germany
(https://dbis.hamburg)
‡ Hamburg University of Applied Sciences (HAW), Hamburg, Germany
(https://www.haw-hamburg.de)
§ University of Oldenburg (Data Science), Oldenburg, Germany
(https://uol.de/data-science)
¶ Baqend, Hamburg, Germany
(https://baqend.com)
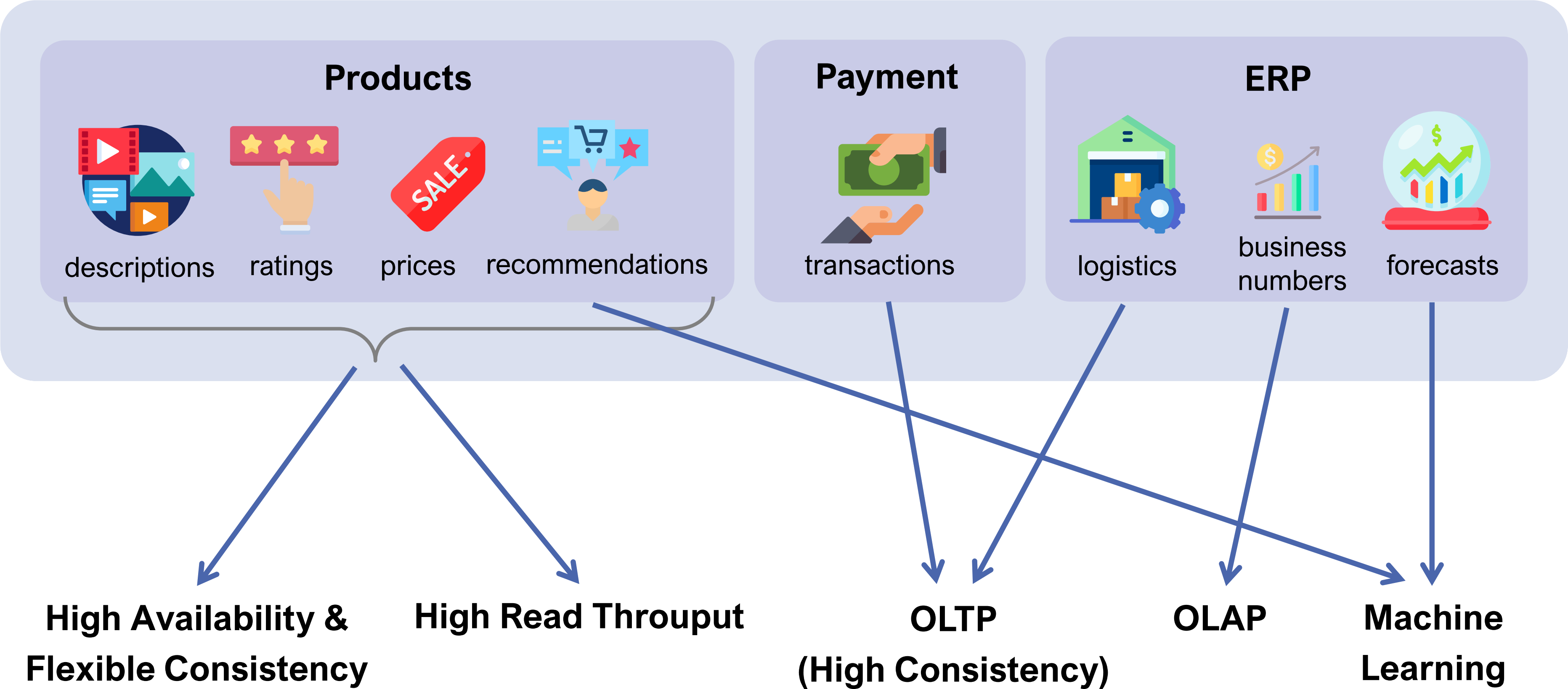
Due to the increasing variety of the current database landscape, polyglot data management has become a hot research topic in recent years. The underlying idea is to combine the benefits of different data stores behind a predefined set of common interfaces and thus address use cases that individual stores cannot meet. This can be accomplished using different approaches which vary greatly in terms of capabilities, functionality, and architectural concepts. This tutorial provides a detailed overview of the current state of research in polyglot data management. We motivate its use by showing the high diversity of existing data stores and discussing three use cases in which individual stores are insufficient. Thereafter, we present different taxonomies for classifying polyglot data systems and give a detailed review of a number of selected systems. Finally, we compare these systems based on their features and discuss open challenges that still need to be addressed in future research.